一、方案简介
农业大数据服务平台主要接入的数据种类有:农业自然资源与环境数据、农业生产与实验数据、其他系统相关数据。

二、方案设计
2.1 数据采集
因农业产生的数据的独特性与多样性,农业大数据分析系统建立数据采集统一标准和异构数据采集交换平台,实现大数据异构数据信息管理。
针对不同作物的数据源的数据特点,数据采集器也是不同的。总体分为三类:关系型数据采集器、实时数据采集器和自定义数据采集器。从数据源采集到的数据先存入临时数据库表,经过验证、清洗和转化存入基础数据库表。基于基础数据库表,会轻度汇总到汇总表中。再以分析主题,把汇总表组成不同主题的分析视图。这里,我们根据分析角度,分成环境资源主题、农业生产主题、农业管理主题、农业流通主题、农业市场主题和农业消费主题。
(智能灌溉数据采集)

(历史蒸发量、降水量、平均温度)

(影响植物生长的因素)

(对水泵电压、电流、水压的监控)

(对蓄水池水量的实时监控)

(对最近三天灌溉水量数据的统计)
2.2 数据分析
针对农业数据的分析处理,在数据量<1TB的情况下,采用关系型数据库来存储数据,并且用SQL执行引擎来进行统计分析。随着数据的不断积累,数据量超过TB级别以后采用分布式计算引擎来进行数据分析处理了。另一方面,当我们有海量的原始数据需要进行初步处理或者结构化数据提取的时候,也需要用到分布式计算引擎。在农业大数据应用中,对于用户行为特征的抽取,对于企业信用信息的抽取,对于气象等环境数据的统计处理,这些都要用到分布式计算引擎。平台上市应用Spark计算框架来实现的。


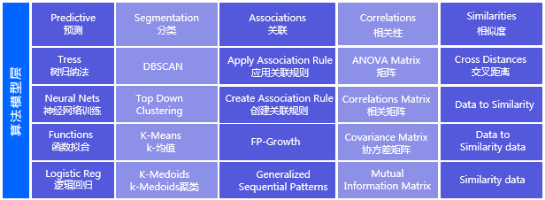
2.3 大数据挖掘
大数据平台提供了数据挖掘和人工智能的算法库,并且还提供了数据建模工具方便用户进行数据清洗,数据建模和数据模型的测试。
大数据平台数据挖掘引擎实现了机器学习算法库与统计算法库,支持常用机器学习算法并行化与统计算法并行化,并利用Spark在迭代计算和内存计算上的优势,将并行的机器学习算法与统计算法运行在Spark上。支持的机器学习算法包括逻辑回归、朴素贝叶斯、支持向量机、聚类、线性回归、推荐算法等,统计算法库包括均值、方差、中位数、直方图、箱线图等。可以支持后期在平台上搭建多种分析型应用,例如用户行为分析、精准营销,将对用户贴标签、进行分类,此类应用都会用到平台的数据挖掘功能。
并集成了RStudio Server,Rstudio是R的一种强大而便捷的IDE,提供基于web的开发环境。同时平台提供的RStudio预加载好了并行化后台以及并行化执行引擎的连接模块,并将R脚本的编写、编译、跟踪执行以及中间变量查看和绘图集于一体,为用户提供了一个强大的R的操作环境。用户除了可以自行编写R的程序脚本、调用开源版本R提供了数千个R的包和函数之外,还可以直接调用并行化机器学习算法库。
2.4 大数据展示
考虑了结构化的数据的展示,使用了数据值直接显示、数据表显示、以及统计图表等形式来表达数据。而大数据处理的为结构化数据种类繁多,关系复杂,传统的显示方法通常难以表现。故针对海量的非结构化数据,在建设过程中,应考虑与地理空间信息相结合,用三维方式来表示复杂信息,让用户直接对具有具体形象的信息操作,方便用户分析结果。同时,需要对农业大数据进行深入研究,根据农业各个领域各个方面的应用,解决农业大数据的上层展现问题,将用户与数据资源融合一起,实现应用交互,便于用户认识、理解数据。



|



